General-Purpose Pre-Trained Models in Robotics
Can we (pre-) train policies to control any robot for any task?

The impressive generalization capabilities of large neural network models hinge on the ability to integrate enormous quantities of training data. This presents a major challenge for most downstream tasks where data is scarce. As a result, we have seen a transformation over the years away from training large models entirely from scratch, and toward methods that utilize finetuning or few-shot learning. Classically, models might be pre-trained on a large-scale supervised or self-supervised task (e.g., pre-training a large ResNet model on ImageNet), and then the last few layers of the model might be fine-tuned on a much smaller dataset for the task of interest. More recently, open-vocabulary vision-language models and promptable language models have made it possible to avoid fine-tuning, and instead define new tasks by constructing a textual prompt, potentially containing a few examples of input-output pairs.

In robotics, learning policies from a small amount of data is even more important. A central benefit of robotic learning should be in enabling rapid and autonomous acquisition of new tasks on command, but if each task requires either a large human-provided demonstration dataset or a long reinforcement learning training run, this benefit will be hard to realize. So how can we develop models and datasets that make it possible to pre-train for a broad range of downstream robotic skills?
In robotics, we must contend with several unique challenges. First, each end-user might have a different robot. While there are a few basic body plans that used widely (e.g., 6 DoF or 7 DoF arms with parallel jaw grippers, quadrupedal walking robots, wheeled ground robots), within each category there is considerable physical and visual variation. It does not seem unreasonable to imagine that a single model could generalize across this variation: after all, a person teleoperating a robot with a joystick is unlikely to be confused by the color of the robot or the shape of its fingers. Second, each end-user is likely to want the robot to perform a different task. Particularly when it comes to robotics research, where researchers might want a large pre-trained model to build on but might still want to solve a new problem, the ability to generalize across tasks is crucial — in the same way that a large language model supports a variety of downstream NLP tasks, a pre-trained robotics model should support a variety of downstream robotic tasks. Third, each end-user will use their robot in a different environment. Even the variability between different robotics labs (much less different real-world deployments) is already likely to put a strain on current robotic learning approaches, which typically use data from a single location collected under laboratory conditions.
Thus, a dataset for pre-training general-purpose robotics models needs to support generalization across:
Robot instances within a category (e.g., all quadrupeds)
Tasks
Environments
For the model that is pre-trained on such a dataset to be useful to downstream users, it also must support finetuning to new tasks, environments, and robots. It would also be beneficial if this model offers at least some few-shot or zero-shot generalization capability — particularly if the goal is to learn downstream tasks with reinforcement learning, the ability to get a good initial policy can greatly improve exploration and radically speed up acquisition of new tasks. Thus, the model needs to:
Support some kind of tasking, prompting, or conditioning to new tasks
Provide a viable mechanism for finetuning with imitation learning, RL, or both
On the other hand, robotics does offer a unique opportunity that could make the burden of constructing such datasets and models significantly lower: downstream applications, particularly those involving autonomous learning (e.g., with reinforcement learning) could collect more data that could be aggregated into a single shared dataset, thus allowing the capabilities of the dataset and any model pre-trained on it to grow over time as it is used more and more.

While a single dataset and model that fulfills all of these requirements does not yet exist, below I will summarize a few recent projects from the RAIL lab at UC Berkeley that addresses some of these requirements in several contexts.
Bridge Data and RoboNet: datasets intended for reuse
We’ve made several efforts at collecting datasets for robotic manipulation that could provide a viable starting point for other researchers to initialize models and obtain good generalization with relatively small amounts of in-domain data. This has been an iterative process, starting with the release of RoboNet in 2019, and continuing with the Bridge Dataset in 2021. Both datasets address some (but not all) of the requirements for a reusable dataset to enable pre-trained models in robotics.
RoboNet is a large, autonomously collected dataset for vision-based robotic manipulation, which contains 7 different robots, with data from 4 institutions, collected via scripted and randomized controllers. The dataset has over 15 million time steps (hundreds of thousands of episodes), and makes it possible to finetune to new robots. However, the fact that all data is collected randomly presents limitations, as it contains only simple object interaction behaviors such as pushing.

We can summarize how RoboNet addresses the requirements laid out previously:
Many robots: yes
Many tasks: no (all tasks are random motions)
Many environments: yes
While RoboNet found some use in the community, it has mostly been utilized for research on video prediction rather than direct robotic interaction. This may be because the random motions are not as useful for supporting more complex downstream tasks: a truly generalizable dataset would need many environments, but also many different tasks.
Bridge Data is meant to address this shortcoming, providing a more focused dataset with one robot (the WidowX 250), but consisting of demonstrations for over 70 different tasks, which are more temporally extended (e.g., picking up and moving objects). To maximize the likelihood that the dataset can be used by other researchers in their own domains, the dataset also includes many different environments.

This dataset also does not fulfill all of the requirements, but it comes close:
Many robots: no
Many tasks: yes
Many environments: yes
While the lack of multi-robot support limits reuse, we can still use this dataset to explore how pretrained models might actually work in robotics.
Pre-Training for Robots with Bridge Data
How can we use Bridge Data to pre-trained large models that can facilitate rapid acquisition of downstream tasks? We’ll start with a method focused on finetuning, by directly applying multi-task offline RL to the Bridge Data to pretrain a multi-task model, and then finetuning this model with a small amount of data for some new task (again with offline RL). In this case, we’ll consider purely offline finetuning, where the new task is defined with a small number of demonstrations (as few as 10 trials). The resulting method, PTR, which is illustrated below, simply uses a one-hot conditioning vector for multi-task training, reserving the last entry in the vector for a new task to be used during finetuning.

PTR can finetune tasks that are similar to those in the Bridge Data to new environments, or finetune the model to tasks that involve new objects and containers, as shown below.

An interesting question to ask in regard to methods such as PTR is the degree to which robotic pre-training actually improves over more general self-supervised pretraining methods that only learn visual representations. The results table below shows PTR (left) and a variety of comparisons. The two comparisons on the right (R3M and MAE) pretrain on much larger non-robotic datasets, and have been shown to yield excellent visual representations in prior work. However, in the few-shot setting, these non-robotic representation learning methods do not yield the same performance as PTR, which pretrains sensorimotor skills directly. That is, PTR actually pretrains on robotic control, learning about the cause and effect structure in the world via offline RL, rather than just acquiring robust visual features.
If we examine the scaling properties of PTR, we see that we enjoy a steady increase in performance as we increase the size of the pre-trained network. These initial results suggest that large pre-trained models in robotics, trained entirely on offline robot data, may enjoy the same benefits of scale seen in other areas of machine learning.

However, PTR is only suitable for finetuning, and does not have zero-shot capability (besides selecting from among the pre-training tasks). It is more akin to classic pre-training and finetuning methods in computer vision (e.g., retraining the last layers of AlexNet), rather than more recent few-shot or zero-shot prompting-based methods. We can summarize its capabilities in terms of the previously mentioned criteria as:
Many robots: no
Many tasks: yes
Many environments: yes
Support tasking: no
Support finetuning: yes
Training taskable models with Bridge Data: FLAP
One way to introduce tasking or prompting is to condition the model on some more flexible representation of the task. Similarly to image-language models, we could use language prompting (see, e.g., SayCan). However, visually indicated goals (i.e., goal images) also provide a simple and easy-to-use option, and avoid costly manual labeling. Some of our recent work has shown that image goal models can be adapted to handle language goals relatively easily using standard image-language models such as CLIP (see, e.g., LM-Nav). So we can focus on visual goals for now, keeping this problem separate from the problem of building a language “front end.”
Here too we can use offline RL (in this case, the IQL algorithm) to pretrain on the Bridge Data and acquire a goal conditioned policy, which can then be “prompted” with different goals at test-time in new environments. However, this presents a few challenges. First, goal-conditioned policies are difficult to train, and might only reliably reach nearby goals. Second, the policy might not be able to reach every user-specified goal in a new test environment, so we need to somehow extend the standard goal-conditioned RL recipe to support finetuning, ideally autonomously.
We recently released a paper describing FLAP, a system that addresses both challenges by combining goal-conditioned offline RL with higher-level planning over learned latent state representations. The intuition behind FLAP is that it is often easier to figure out high-level subgoals (e.g., to put an object in a pot, we should first grasp the object, then place it) then to figure out how to execute each subgoal (e.g., how to actually grasp a new object successfully). FLAP learns a lossy representation of the state during the offline RL process, and then learns a multi-step predictive model over this representation that can be used to plan subgoals. This allows it to reach more distant goals through planned subgoals, addressing the first challenge. But perhaps more importantly, when the user gives the robot a new goal in a new domain, FLAP can plan subgoals to this goal (relying on the fact that the higher-level model is using a more abstracted and generalizable representation), and then autonomously finetune the low-level policy by practicing these intermediate subgoals.

Thus, a practical application of FLAP as a pre-trained model might involve a user loading up the model on their robot, specifying a goal image (e.g., by positioning objects in the environment with their own hands), and then letting FLAP compute suitable subgoals and, if the method is not successful on the first try, run some amount of online RL finetuning by practicing these subgoals.

FLAP illustrates how taskable or promptable models in robotics can expose some unique capabilities: besides solving new tasks in zero shot, FLAP can utilize online RL to autonomously finetune for the new task. This finetuning falls somewhere in-between the traditional supervised finetuning regime in computer vision and the more modern zero-shot prompting: although the task is not solved in zero shot, it arguably is solved at much lower burden to the user, since the robot can perform the finetuning on its own. Conceivably, the data collected in this way could then be added back to the Bridge Dataset. Referring back to our checklist, FLAP looks like this:
Many robots: no
Many tasks: yes
Many environments: yes
Support tasking: yes
Support finetuning: yes
General Navigation Models (GNMs): learning to drive any robot
So what about training a single backbone model that can generalize to many different robots? If the training data contains enough different robots, a high-capacity model should be able to generalize to new robots in zero shot, and then further finetune if it’s performance is insufficient. We investigated this possibility in the domain of robotic navigation, where data is comparatively more plentiful and it’s possible to find existing datasets from a variety of robotic platforms. To this end, we developed General Navigation Models (GNMs), which are simple goal-conditioned models (similar to FLAP) that use visually indicated goals, and then graph search on a topological graph to plan a path to distant goals.
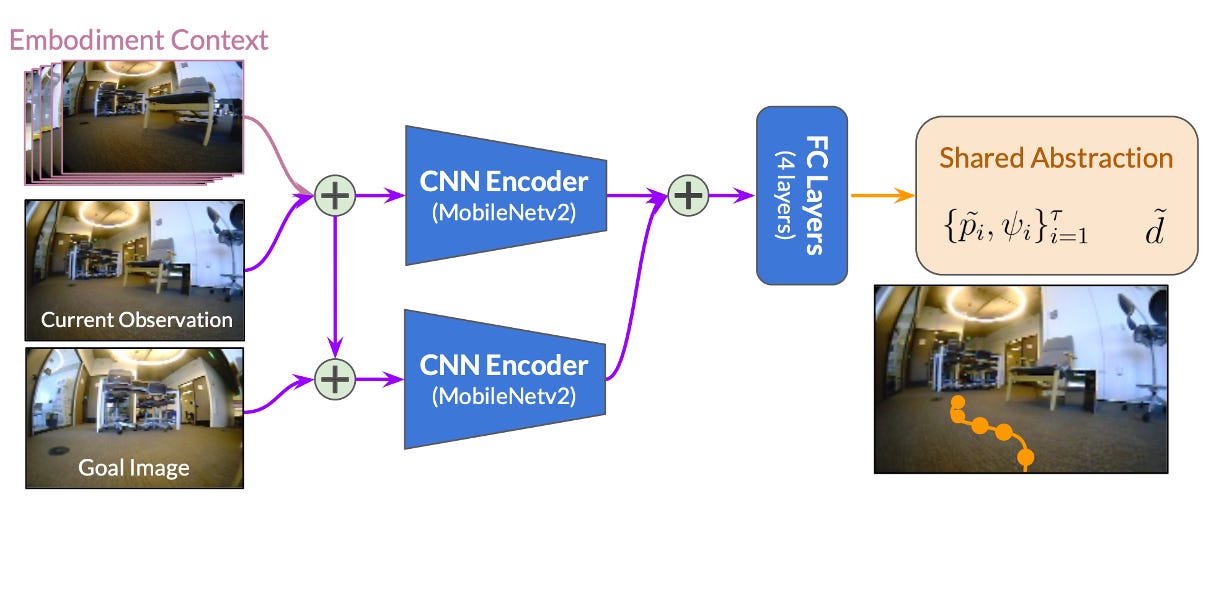
We assembled a dataset consisting of data from six different robots spanning a wide range of scales, from full-size vehicles to small-scale RC cars. The largest robots drove at up to 10 m/s, and the smallest at 0.5 m/s.

Note that GNMs do not use any special training procedure to combine data from multiple robots — there is no domain adaptation or explicit transfer learning, just raw generalization from data of many different robots. Perhaps surprisingly, GNMs can generalize to entirely new robots from just this dataset. In fact, the GNM could even fly a quadcopter at a fixed height through hallways (see below) without any additional training, and without having ever seen any data from a quadcopter.

Perhaps these results are less surprising if we consider that all of these navigation tasks have a great deal of shared structure. Still, the fact that a single model could be trained to control such a wide variety of test robots, including ones that were never seen before, and could do so in a wide range of environments and for a wide range of goals, suggests that multi-robot pre-trained backbone models could be quite feasible with the right dataset. Referring back to our checklist, GNMs look like this:
Many robots: yes
Many tasks: yes (in the sense that different goals are different navigational tasks)
Many environments: yes
Support tasking: yes (in the sense that the user can specify the goal)
Support finetuning: unknown (we didn’t try this yet!)
GenLoco: learning to walk any robot
We can also train multi-robot policies for more physically complex domains. In GenLoco, we studied how a single policy could be trained to control a wide variety of different quadrupedal robots, using simulated training with heavy randomization.

This not only results in a policy that can control a variety of different robots in the real world, but actually results in more robust controllers for the robots seen in training, due to the increased variability that the policy is forced to handle. This agrees also with our experience with GNMs, where we also found that GNMs were more robust to minor physical modifications (changes to camera placement, damage to tires) than single-robot policies.

The previously discussed methods all use real data, while GenLoco relies on simulation. However, it still serves as an important proof-of-concept that learned policies can generalize across robots even for more physically complex control tasks.
Many robots: yes
Many tasks: no (each GenLoco policy performs a specific task)
Many environments: no (though we could vary environments!)
Support tasking: no
Support finetuning: unknown (we didn’t try this yet!)
Concluding Remarks
Large, high-capacity, multi-task models that can control a wide variety of robots, generalize across environments and tasks, receive task specification in zero shot, and then finetune (perhaps even autonomously with RL!) present a transformative capability for robotic learning. If the overhead for each robotic learning experiment is reduced to supplying a few demonstrations, a handful of goal examples, a reward function, or even just a single image or language description, then robotic learning methods will be far more broadly applicable and flexible. Perhaps the most important question to ask in this area is: if a researcher or practitioner gets a new robot, can they load up some high-capacity pre-trained model on this robot and start getting reasonable behavior straight out of the box?
While none of the methods I discussed in this article fully enable this capability just yet, we are getting closer and closer. GNMs can already provide basic navigational functionality to robots with forward-facing cameras, and extending the methodology in FLAP and PTR to multi-robot settings may already provide a viable initialization for a wide range of robotic manipulation skills. However, these experiments also may raise a number of questions about alternative directions that we might pursue, and while the particular design of these models and corresponding datasets remains an open question, I’ll discuss some of the more likely criticisms and alternatives below.
Can we just use videos from the Internet? The use of computer vision data and videos of humans is an active area of research in robotics. I think this is an important direction to pursue for improving visual representations, and one that can further improve robustness and generalization. However, I also believe that in order for pre-trained models in robotics to enable very rapid (even zero-shot) acquisition of new tasks, they will need to also use large amounts of real-world robot data. The reasons for this are perhaps best illustrated by the PTR experiments, which showed that pre-trained visual representations (i.e., R3M and MAE) did not lead to nearly the same level of performance as PTR. This should not be surprising: robot data tells the model how to actuate the robot to perform a task, while image and video data tells it how to perceive the visual world. While visual perception is important, it does not by itself capture the nuances of physical interaction. Put another way, imagine learning to play tennis: no matter how many times you watch Roger Federer, you will not become a tennis champion unless you actually pick up the tennis racket. However, on the flip side, I also think that the difficulty of obtaining large robotic datasets tends to be grossly overstated in the research community. As I discussed in my recent article, robotic data should be relatively cheap because it can be collected autonomously. And when it comes to large pre-trained models, if our aim is to have dataset that is general and broadly applicable, it also hopefully would only need to be collected once, after which it can enjoy the benefits of perpetual growth as users add their own robot’s experience to it after using the corresponding pre-trained models.
Can we just use simulators? Simulation is a very powerful tool in robotic learning. GenLoco used simulation to simulate a variety of robot morphologies to enable generalization across robots, and numerous recent works have shown that in some domains, such as locomotion, it can be used to obtain powerful and generalizable policies for real-world robotic tasks. However, I believe that in the long run, we will see real data subsume the use of simulation, perhaps for a somewhat unexpected reason: in the end, real data will simply be easier to get. This might seem surprising against the backdrop of current robotics research, but there is a reason that simulated data is rarely used in computer vision and natural language processing: once a critical mass of real-world data is available, the engineering and content creation overhead of simulation is simply not worth it. Of course, we might learn a simulator from data, but at that point we are back to the same place: using real-world data to enable (in this case, model-based RL) training. Real-world data has many appealing advantages: it reflects the world as it really is, when it can be collected in realistic environments (as in the navigation examples for GNMs) it can reflect a very broad cross-section of real-world situations without any content creation cost, and it can grow naturally as practitioners and researchers use robots more and more.
Why is all this interesting for machine learning researchers? While this is not a technical criticism per se, it is a valid question for any researcher to ask: why should they worry about robotic learning, when powerful pre-trained models for language, image generation, and classification offer so many low-hanging fruits and a plethora of exciting capabilities? I believe that robotic learning provides some unique opportunities that make it far more interesting. Although the up-front challenge of assembling a dataset suitable for building pre-trained robotic models is high, once such a dataset exists, the resulting models can done some very interesting things. In standard machine learning application domains, whether a model is fine-tuned or prompted, the learning process in the end is non-interactive: data is obtained from humans, and it is difficult to improve a model after deployment. The robotics setting offers a much richer range of choices, with autonomous finetuning, interactive prompting, and online exploration. This makes the prompting and finetuning aspects of the problem far more interesting, and presents many more technical opportunities for researchers to develop unique and powerful algorithms (see, also, this article). Pre-trained robotic models can bootstrap a process of perpetual and autonomous self-improvement, which can then snowball into a fully autonomous data gathering “flywheel” that makes robots more and more capable the more they are used. It’s an exciting prospect to imagine watching our robots “grow up” in this way, and to me this makes it the most exhilarating research area today.
This article covers similar materials to a recent talk on pre-trained models in robotics:
The research discussed in this article is described in the following papers:
Sudeep Dasari, Frederik Ebert, Stephen Tian, Suraj Nair, Bernadette Bucher, Karl Schmeckpeper, Siddharth Singh, Sergey Levine, Chelsea Finn. RoboNet: Large-Scale Multi-Robot Learning. CoRL 2020.
Frederik Ebert, Yanlai Yang, Karl Schmeckpeper, Bernadette Bucher, Georgios Georgakis, Kostas Daniilidis, Chelsea Finn, Sergey Levine. Bridge Data: Boosting Generalization of Robotic Skills with Cross-Domain Datasets. RSS 2022.
Aviral Kumar, Anikait Singh, Frederik Ebert, Yanlai Yang, Chelsea Finn, Sergey Levine. Pre-Training for Robots: Offline RL Enables Learning New Tasks from a Handful of Trials. 2022.
Kuan Fang, Patrick Yin, Ashvin Nair, Homer Walke, Gengchen Yan, Sergey Levine. Generalization with Lossy Affordances: Leveraging Broad Offline Data for Learning Visuomotor Tasks. CoRL 2022.
Dhruv Shah, Ajay Sridhar, Arjun Bhorkar, Noriaki Hirose, Sergey Levine. GNM: A General Navigation Model to Drive Any Robot. 2022.
Gilbert Feng, Hongbo Zhang, Zhongyu Li, Xue Bin Peng, Bhuvan Basireddy, Linzhu Yue, Zhitao Song, Lizhi Yang, Yunhui Liu, Koushil Sreenath, Sergey Levine. GenLoco: Generalized Locomotion Controllers for Quadrupedal Robots. IROS 2022.
Model based RL is essential for efficient learning. Unfortunately your model learning network needs to
learn incrementally from data under distribution shift. This needs continual learning , growing network capacity, plasticity. One reason why current deep learning nets can't handle well model based RL.
Interesting paper: Mastering Atari Games with Limited Data: https://arxiv.org/abs/2111.00210
Though still limited to simple environments
Despite the recent progress in the sample-efficient RL, today’s RL algorithms are still well behind human performance when the amount of data is limited. Although traditional model-based RL is 2 considered more sample efficient than model-free ones, current model-free methods dominate in terms of performance for image-input settings. In this paper, we propose a model-based RL algorithm that for the first time, achieves super-human performance on Atari games with limited data.
Through our ablations, we confirm the following three issues which pose challenges to algorithms like MuZero in data-limited settings.
- Lack of supervision on environment model.
- Hardness to deal with aleatoric uncertainty.
- Off-policy issues of multi-step value.
To address the above issues, we propose the following three critical modifications, which can greatly improve performance when samples are limited.
- Self-Supervised Consistency Loss
- End-To-End Prediction of the Value Prefix
- Model-Based Off-Policy Correction