Sporks of AGI
Why the Real Thing is better than the Next Best Thing

Training big models is really hard, and as the models get bigger and expand into new domains, it’s only getting harder. LLMs use lots of text data, while VLMs require data with text and images, and vision-language-action (VLA) models in robotics require lots of data of robots performing real tasks in the real world. This hits agents especially hard: whether you want to control a real-world robot or take actions to fulfill user requests on the web, data of real-world interactions with action labels can’t be obtained as cheaply as text and images from the web. It’s no wonder that researchers have been trying to find a way to substitute the Next Best Thing in place of real data with observations and actions, in an attempt to get a best of both worlds: the power and generalization that comes with training huge models on huge datasets, at a cost that is much lower than standard methods for training foundation models on in-domain data.
The Next Best Thing
While authentic real-world data has always been preferred for visual perception and NLP, when it comes to agents – and robotic agents in particular (e.g., VLAs), – there is an irresistible urge to figure out how to use something else, some sort of surrogate data that can be obtained on the cheap but still provide the kind of broad generalization we expect from foundation models. I’ll focus on robotics in this article, but other domains follow a similar script though with different actors. Simulation is a classic option. If we can just figure out how to train robots in The Matrix or in a really good video game, maybe we can avoid the need for real data. Other options include using videos of people, perhaps scraped from the web, or hand-held gripper-like devices that people can use to record videos of themselves performing tasks in a more robotic way. While there has been a great deal of exciting and amazingly creative research in this area, we can, at the risk of drawing a caricature, describe it as follows: manually define a mapping or correspondence between a cheap surrogate domain and the real world robotic system, and then leverage this correspondence to use this cheap data instead of expensive but representative in-domain data (i.e., data from the real robot in the real target domain). Each of the widely studied methods for avoiding the need for real-world robot data is predicated on some idea of this sort:
Simulation: sim-to-real methods require a human designer to specify the environments in which the robot is trained and produce the requisite assets. The behavior learned in the sim is a product of these choices. Often the simulations that lead to the best results don’t so much present an accurate model of reality (which is very hard), but rather encode the types of variation that the robot should be robust to, such as training on random stepping stones or height fields, further underscoring how human insight informs not just what the task is, but indirectly how it should be solved.
Human videos: methods that learn robotic skills purely from videos of people typically need to define some kind of correspondence between humans and robots, such as the position of the hand or finger placements for grasping. Any such choice presumes a particular way of solving the task (e.g., by picking up and moving items with the hand using a power grasp), and also requires bridging the considerable gap between physically feasible human movements and robot movements, both in terms of dynamics and appearance.
Hand-held gripper devices: instead of defining the mapping in the learning process, we can impose a human-robot mapping physically, by asking people to collect data using hand-held devices that mimic robot grippers. This is really appealing, because then people have to perform the task in a robot-like way. But the same kind of “how” decision is still needed – e.g., the device assumes that the robot will perform the task in the kinematic workspace where it has full 6 DoF dexterity, using only the fingers, and in a way that does not reveal discrepancies between human and robot kinematics or appearance.
All of these methods make for interesting and relevant research, and all have led to some excellent and exciting practical results. However, I would argue that in the limit, each of them represents a compromise that ultimately undermines the real power of large learned models.
The Intersection
Of course human judgement is inescapable when collecting data: even the most authentic and pure blank-slate learning approach requires us to define something about what we want the model to do. But the design decisions we make when we try to dodge the need for real data can be particularly troublesome, because they inherently constrain how the problem can be solved. With each domain gap (simulation, videos, etc.), we are constrained to solutions that lie in the intersection of behaviors that actually work with our system, that can be done with our method of choice (e.g., in simulation, or with hand-held grippers) and, crucially, that do not exacerbate the difference between the domains (e.g., revealing that there is no robot holding the gripper, or surfacing a particularly severe simulation/real-world discrepancy). Furthermore, as we use larger and more powerful models, we should expect to feel stronger headwinds from these issues: as more powerful models fit the patterns in the data more tightly, they’ll increasingly fit to the discrepancies just as much as they fit to the real transferable patterns we want to learn.
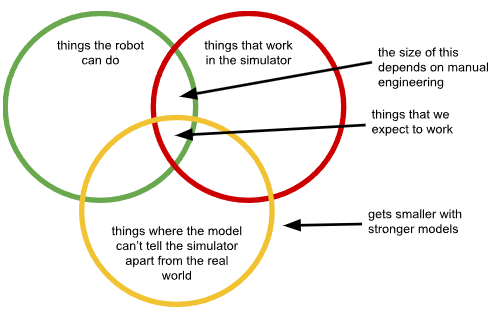
These issues can seem innocuous in research projects and demos, because we can set up the real robot in a way that makes this discrepancy less important, selecting tasks, environments, and objects where the best and most robust strategies lie precisely within this intersection. But in real open-world environments, this is not only limiting, but actually undermines the main advantage of training large and powerful foundation models.
First, as the model gets stronger and stronger, and thus can better distinguish between the surrogate data domain and the target real-world domain (i.e., the yellow circle shrinks), this intersection gets smaller. We can try to counteract this issue by hiding information from the model, reducing the observation space, using domain invariance losses, restricting the camera views that the robot can use, and so on. Virtually every method for addressing these domain discrepancies boils down to some sort of information hiding. But this again undermines the main advantage of foundation models, which is their ability to synthesize complex information sources and extract subtle patterns that are hard for humans to identify manually. Basically, the yellow circle gets smaller as we use stronger models, and any attempt to counteract this has to in the end make the models weaker. We can only “fool” our models and prevent them from realizing that they are in The Matrix by lobotomizing them.
The size of this intersection also depends critically on the design decisions we make in designing our surrogate data – the worse these design decisions, the smaller the intersection between the green and red circle will be. In practice, we design the setup for our surrogate data (our simulator, or hand-held data collection device) so that the discrepancy is minimized in a few application domains that we have in mind, such that good actions (i.e., those that lead to success, or at least avoid catastrophic failure) match between the surrogate and the real robot within those application domains. But there is no guarantee that they will match outside of it. Essentially, when we train our robotic foundation model on, for example, human data, and then present it with a new problem, it will try to predict how a human will approach this problem, rather than predicting an effective strategy for a robot. This again acts against the main advantage of foundation models – namely, their generality to be applied to many problems and their capacity for generalization in extrapolating the training patterns to new test domains. Now, each new domain requires more manual engineering to improve our correspondences, and the model’s generalization capacity actually acts against us, exacerbating the gap between the surrogate data and the real robot as we try to generalize to more novel situations.
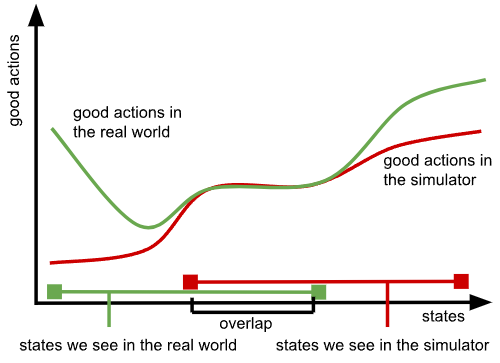
All these issues become even more exacerbated when we actually want to optimize for the best possible behavior (e.g., with reinforcement learning), since we can’t leverage the full capacity of the real robotic system without stepping outside of the narrow intersection of things the robot can do, things that work in the surrogate data, and things where the model can’t tell the difference.
The Real Thing
In trying to dodge the need for using real-world data, we are trying to find a best of both worlds solution: something that is as cheap as simulation or videos from the web, but as effective as real foundation models trained on large datasets. What we get is a spork: it can do the job of both a fork and a spoon in a few cases that match our assumptions, but usually it ends up just being a lousy spoon with holes or an ineffective blunt fork.
What consistently works best in machine learning is to ensure that the training data matches the test conditions. That is the Real Thing – the data that teaches the model about how the world really works, so that it can do its job and extract the underlying patterns, many of which are too subtle and complex even for humans to understand, and then extrapolate from these patterns to solve complex new problems. When we substitute out real data for surrogate data, we are doing the Next Best Thing: a surrogate that matches the real deal under a few specific conditions. Just like you won’t become an expert tennis player by hitting balls against the backboard or watching Roger Federer on TV, even though both replicate some aspects of the true tennis pro experience, the robot won’t master the real world unless it gets to see itself doing stuff in the real world.
What should we take away from this? The main takeaway is that real data is indispensable if we are to truly build robotic foundation models that can generalize in the real physical world as broadly as LLMs and VLMs do in the virtual world. But we should also not throw out the baby with the bathwater: it’s important to remain pragmatic, and just like LLMs and VLMs use huge amounts of data that is much less relevant to their ultimate purpose yet contains useful world knowledge, so too our robotic foundation models could use many diverse sources of data. After all, watching Roger Federer is useful if you want to be a good tennis player. If we include diverse data, including data from humans and even simulation, in our training set in addition to broad and representative real-world robotic experience, this is likely to help. In fact, it’s likely much easier than trying to dodge the need for real-world data entirely: if we no longer need to worry about learning only in the intersection of robot capability and our surrogate data coverage, it’s okay to dispense with crutches aimed at reducing the domain gap, and embrace the surrogate data for what it is: an auxiliary source of knowledge that can help you become a good tennis player that is meant to supplement rather than replace large amounts of real-world hands-on experience. With this perspective, we might also put very different requirements on our surrogate data: instead of trying to closely match the real-world robot embodiment (e.g., by using hand-held grippers, or asking people to move like robots in a video), we would instead use surrogate data like we use pretraining data for LLMs – a source of knowledge about what can happen in the real world, rather than direct instructions for what the agent should actually do.
The Sporks
In this article, I discussed surrogate data, a spork that tries to get the benefits of large-scale training without the cost of large-scale in-domain data collection. This is not the only spork that AI researchers are fond of. Other sporks include hybrid systems that combine hand-engineered and learned components, methods that use hand-designed constraints to limit undesirable behavior of learned autonomous systems, and models that embed our intuition of how the problem ought to be solved into the architecture of the neural network itself. They all try to get the best of both worlds: the benefits of large-scale machine learning without the accompanying downsides of high data requirements or extensive objective design (“alignment” or “post-training”). At some deep level, they have a lot in common – addressing the challenge of incomplete training with some form of hand-designed inductive bias. They therefore have the same fundamental downside: they require us to build in how we think we think. The success of large-scale machine learning comes down to the power of ML over human design, what Richard Sutton calls the Bitter Lesson. A corollary to the Bitter Lesson is that, for any learning-enabled system, any component that is not learned but instead designed by hand will eventually become the bottleneck to its performance. Sporks are appealing because they make us think that we can overcome major challenges in AI by forcing the model to solve the problem in a particular way, but in the end this makes our learning systems less scalable, even if our intent is to do precisely the opposite.
Thank you to Karol Hausman, Brian Ichter, Lachy Groom, and Chelsea Finn for feedback on an earlier version of this article.
I suppose this is an article meant to target VC types or something because it lacks the usual depth we are used to from Sergei. While I appreciate the discussion, I can't help but point out it in essence a tautology. «The best thing to train on is the thing itself» is immediately self-evident. A more nuanced discussion we are avoiding here is «how much» of the real thing do we need? In your tennis example, you can get pretty strong at playing tennis if you just do drills, then simply transition to playing strong real players. Still, the bulk of the skill development is done on surrogates. I don't think we need every robot to be Roger Federer, although it's a great goal. (I am a tennis fanatic). By the by, I think we can both agree the solution is not a farm of cheap arm operators in a third-world country collecting datasets from scratch for every single thing they can imagine we would like to do. There is no escaping the inductive biases of humans -- they exist in all solutions! Hand-held grippers, simulator design, and 1-to-1 same robot demonstrations. I come from the LLM world, but I dabble in robotics -- please refute me if you fancy!
This article makes me wonder: what do we consider to be “real-world” data? A model trained on robot data from human teleoperation will learn to solve problems in the way that a human teleoperating a robot would. What are the "gold labels" for real-world robot data? Is it data or gradients from real-world RL? Or will it be from offline RL/success-filtering on data from deployed “spork” models (the data flywheel)?