

Language Models in Plato's Cave
Why language models succeeded where video models failed, and what that teaches us about AI

From its original inception, the study of artificial intelligence has been intertwined with the quest to understand human intelligence. Predicated on the notion that the mind is fundamentally computational – that is, it can be modeled as an algorithmic framework independently of its underlying computational substrate or “hardware,” – AI researchers have sought to draw inspiration from what we understand about the mind and the brain to construct artificial minds that reflect the flexibility and adaptability of human intelligence. Some researchers have even speculated that the complexity and flexibility of the mind is derived from a single algorithm applied throughout the brain to acquire all of its diverse capabilities. This hypothesis is particularly appealing for AI researchers, as it suggests that our job might actually be quite simple. Instead of painstakingly designing all of the functions that we would want an artificial mind to perform, we might only need to discover this single ultimate algorithm, and then let it loose on the real world to acquire all the capabilities of the human mind through direct experience.
Large language models (LLMs) have been very successful at emulating certain aspects of human intelligence, and while there is no question that there are still gaps in their capabilities – gaps that are big enough to fit even the most fundamental criticisms – the LLM approach to AI has repeatedly overcome major challenges and objections, acquiring new cognitive capabilities with each order of magnitude increase in model and dataset size. The algorithms underlying LLMs, based on next token prediction and RL-based fine-tuning, are also remarkably simple. This might lead us to suppose that these algorithms might actually resemble the hypothetical single ultimate algorithm that the brain uses to acquire all of its diverse capabilities. If true, this would be exceptionally appealing. Not only can human intelligence solve a huge range of problems, but it can also discover new solutions to entirely new problems. Humans have come to dominate the world around them not because of our ability to recall facts or solve math problems, but because of our ability to quickly learn from experience and adapt to novel situations. Capturing this capability in an AI system would be a tremendous leap forward.
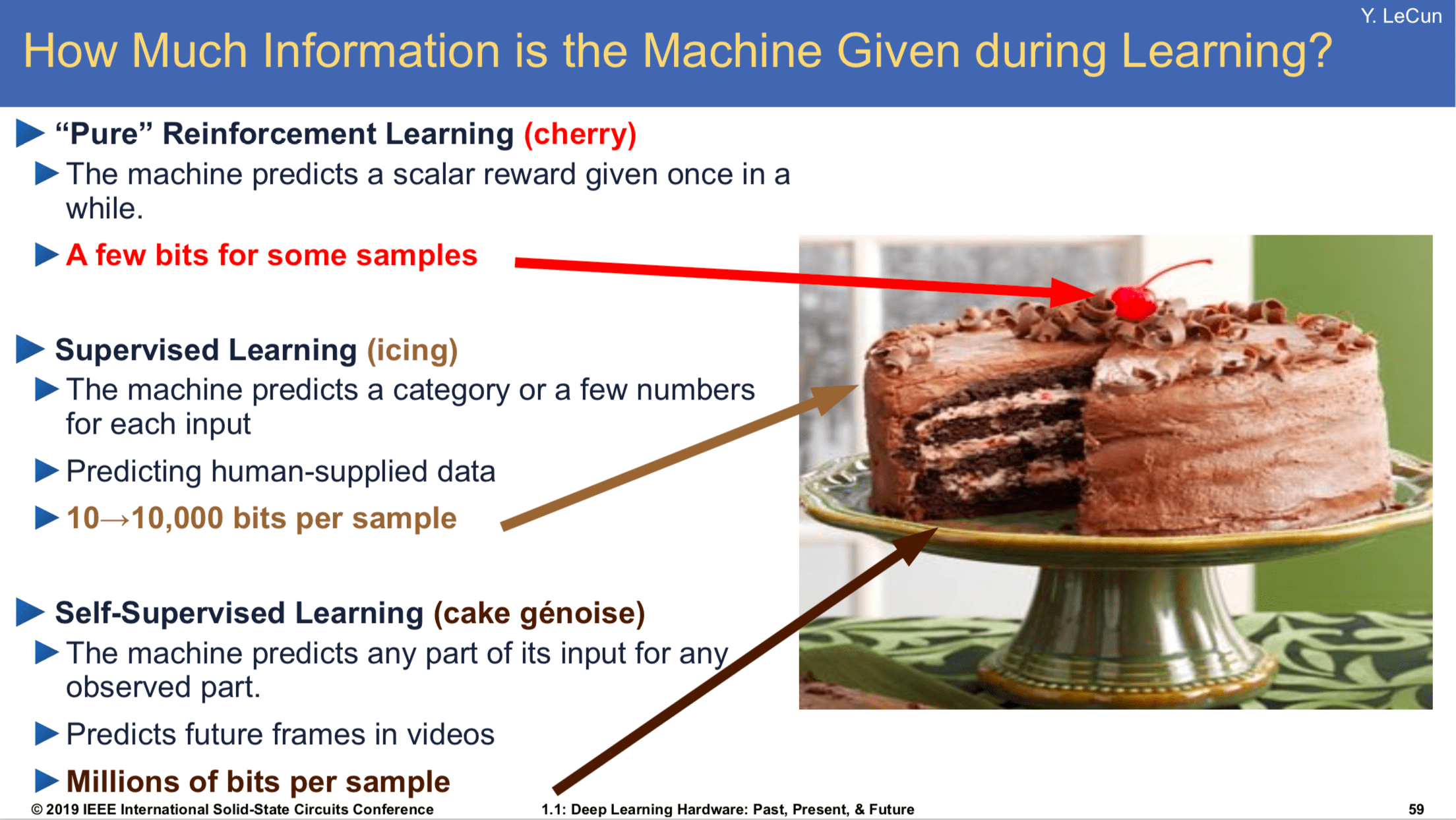
There is however a crack in the foundation of this argument. Even before the earliest Transformer-based language models, AI researchers were busy studying a seemingly very similar problem: analogously to next-token prediction in LLMs, researchers had tried for about a decade to extract meaningful representations and physical understanding by training models for next-frame prediction on videos. On the surface this problem seems very similar: just like an LLM derives a deep understanding of the world by predicting the next token in textual data from the web, a video model might derive a deep understanding of the world by predicting the next frame in video data. In many ways this is even more appealing and seemingly more powerful: video data contains a lot more information (cf. Yann LeCun’s cake), it can be obtained in huge quantities not just from the web, but simply by pointing a camera at a busy street, and it can capture not just the words that people use to communicate with each other, but also the richness and complexity of the physical universe. A robot that flies away to explore a distant planet, like a person stranded on a desert island, wouldn’t benefit much from learning via next-token prediction on text, since there would be no one to provide it with text there, but it can still obtain plentiful video data. Unfortunately, things didn’t pan out the way that video prediction researchers had expected. Although we now have models that can generate remarkably realistic video based on user requests, if we want models that solve complex problems, perform intricate reasoning, and make subtle inferences, language models are still the main and only option. We can’t ask Veo 3 to estimate whether the island of Hawaii contains more cubic meters of rock than Mt. Everest, but ChatGPT can complete that task with gusto. This might seem like a mystery, since LLMs “see” much less of the physical world, and are seemingly exposed to a much thinner slice of reality, and yet acquire much more sophisticated cognitive abilities even when it comes to spatial and physical inferences.
{kind=link}
In science, we might suppose that the more simple, elegant, and powerful a theory is, the more likely it is to be the right one – there are many ways to write down an equation to describe the oscillation of a spring, but we take Hooke’s law to be the “right” theory because it provides both remarkable simplicity and high predictive power. Similarly, we might suppose that if we have an algorithm that is simple, elegant, and explains similar essential functions as the human mind, then it is likely to be the right model of the mind’s computational processes. That is, if LLMs are trained with a simple algorithm and acquire functionality that resembles that of the mind, then their underlying algorithm should also resemble the algorithm by which the mind acquires its functionality. However, there is one very different alternative explanation: instead of acquiring its capabilities by observing the world in the same way as humans, LLMs might acquire their capabilities by observing the human mind and copying its function. Instead of implementing a learning process that can learn how the world works, they implement an incredibly indirect process for scanning human brains to construct a crude copy of human cognitive processes.
Of course, there are no people strapped to fMRI machines in data centers that train LLMs (that I know of). Instead of directly scanning real live brains, LLMs reconstruct the human mind through the shadow that it casts on the Internet. Most of the text data on the web is there because a person pressed buttons on a keyboard to type out that text, and those button presses were the result of mental processes that arose from underlying cognitive abilities: solving a math problem, making a joke, writing a news story. By acquiring compressed representations of this text, the LLM is essentially trying to reverse engineer the mental process that gave rise to it, and indirectly copying the corresponding cognitive ability. While the Human Connectome Project is busy reconstructing the human brain neuron by neuron, LLMs are trying to skip the neurons all together and reconstruct the mind from the shadow it casts on the Internet.
This explains why video prediction models that learn about the physical world have so far not yielded the same results as next-token prediction on language: while we might hope that models that learn from videos might acquire representations of the physical world in the same way that humans learn through experience, the LLMs have managed to skip this step and simply copy some aspects of human mental representations without having to figure out the learning algorithm that allowed humans to acquire those representations in the first place.
This is both exciting and disappointing. The good news is that we’ve been able to build the world’s most powerful brain scanner without even intending, and it actually works, simulating at least some fraction of human cognitive ability in an AI system that can answer questions, solve problems, and even write poems. The bad news is that these AI systems live in Plato’s Cave. The cave is the Internet, and the light shines from human intelligence, casting shadows of real-world interactions on the cave wall for the LLM to observe. In Plato’s allegory, leaving the cave and observing the world in daylight is necessary to understand the world as it really is. The shadows on the wall are only a small, distorted piece of reality, and crucially the observer in the cave doesn’t get to choose which shadows are presented to them. AI systems will not acquire the flexibility and adaptability of human intelligence until they can actually learn like humans do, shining brightly with their own light rather than observing a shadow from ours.
In practice, this means that we would expect LLM-like AI systems to be proficient in reproducing human-like cognitive skills, but relatively poor at actually acquiring new skills, representations, and abilities from experience in the real world – something that humans excel at. It also implies that implementing this kind of flexibility would require us to figure out something new: a way to autonomously acquire representations from physical experience, so that AI systems do not need to rely on brain scans mediated by text from the web.
However, as AI researchers and engineers, we should also be pragmatists: these brain scan LLMs are really good, and if we want to reproduce a human-like mind in a machine, starting with a good working prototype seems like a great idea. The challenge AI research faces over the coming decade is how to extract the right lesson from the success of LLMs, but also discover the principles that underlie real flexible and adaptive intelligence – the kind that can learn from experience, understand the physical world, and discover entirely novel solutions to new problems that no human being had solved before.
I would like to thank Chelsea Finn for feedback on an earlier version of this article. The title image is from Wikimedia commons.
{kind=link}
I evaluated LLMs on hidden Markov models (observations are emitted from hidden Markovian states), and found that in-context learning along can get to optimal next-observation prediction accuracy. Notably, it's under a condition where it's relevant to your observation -- when the entropy of observation to hidden state is low. Feel free to check https://arxiv.org/pdf/2506.07298 for details.
Language is a tool for humans to communicate, so the tokens are extremely efficient in capture the latent representations. However, in real world, like videos, or images, or any signals in nature, the underlying physics is much more complex. But I am hopeful that we can still build good algorithms and scale it up to learn something great.
But video generation models trained autoregressively do seem to solve vision just as language models solve language. They capture structure, object permanence, physical causality, and coherent dynamics. I think autoregression may well be the unifying principle, the engine running across all these separate, generative systems.
The kind of “understanding” you say is missing—symbolic reasoning, abstraction, generalization—doesn’t reflect a shortcoming of vision models or autoregression generally. It reflects the absence of a bridge between modalities. Each system—vision, language, action—is its own separate cave, with its own internal structure and generative logic. The real challenge isn’t escaping the cave; it’s connecting them.
The recent paper Harnessing the Universal Geometry of Embeddings paper offers a promising approach: align these modular embeddings through shared structure, not symbolic translation. But there are likely other possible approaches.
Either way I think we’re tantalizingly close to the grand unified vision.